Теорема сложения дисперсий. Расчёт групповой, межгрупповой и общей дисперсии (по правилу сложения дисперсий)
Теория вероятности - особый раздел математики, который изучают только студенты высших учебных заведений. Вы любите расчёты и формулы? Вас не пугают перспективы знакомства с нормальным распределением, энтропией ансамбля, математическим ожиданием и дисперсией дискретной случайной величины? Тогда этот предмет вам будет очень интересен. Давайте познакомимся с несколькими важнейшими базовыми понятиями этого раздела науки.
Вспомним основы
Даже если вы помните самые простые понятия теории вероятности, не пренебрегайте первыми абзацами статьи. Дело в том, что без четкого понимания основ вы не сможете работать с формулами, рассматриваемыми далее.
Итак, происходит некоторое случайное событие, некий эксперимент. В результате производимых действий мы можем получить несколько исходов - одни из них встречаются чаще, другие - реже. Вероятность события - это отношение количества реально полученных исходов одного типа к общему числу возможных. Только зная классическое определение данного понятия, вы сможете приступить к изучению математического ожидания и дисперсии непрерывных случайных величин.
Среднее арифметическое
Ещё в школе на уроках математики вы начинали работать со средним арифметическим. Это понятие широко используется в теории вероятности, и потому его нельзя обойти стороной. Главным для нас на данный момент является то, что мы столкнемся с ним в формулах математического ожидания и дисперсии случайной величины.

Мы имеем последовательность чисел и хотим найти среднее арифметическое. Всё, что от нас требуется - просуммировать всё имеющееся и разделить на количество элементов в последовательности. Пусть мы имеем числа от 1 до 9. Сумма элементов будет равна 45, и это значение мы разделим на 9. Ответ: - 5.
Дисперсия
Говоря научным языком, дисперсия - это средний квадрат отклонений полученных значений признака от среднего арифметического. Обозначается одна заглавной латинской буквой D. Что нужно, чтобы её рассчитать? Для каждого элемента последовательности посчитаем разность между имеющимся числом и средним арифметическим и возведем в квадрат. Значений получится ровно столько, сколько может быть исходов у рассматриваемого нами события. Далее мы суммируем всё полученное и делим на количество элементов в последовательности. Если у нас возможны пять исходов, то делим на пять.

У дисперсии есть и свойства, которые нужно запомнить, чтобы применять при решении задач. Например, при увеличении случайной величины в X раз, дисперсия увеличивается в X в квадрате раз (т. е. X*X). Она никогда не бывает меньше нуля и не зависит от сдвига значений на равное значение в большую или меньшую сторону. Кроме того, для независимых испытаний дисперсия суммы равна сумме дисперсий.
Теперь нам обязательно нужно рассмотреть примеры дисперсии дискретной случайной величины и математического ожидания.
Предположим, что мы провели 21 эксперимент и получили 7 различных исходов. Каждый из них мы наблюдали, соответственно, 1,2,2,3,4,4 и 5 раз. Чему будет равна дисперсия?
Сначала посчитаем среднее арифметическое: сумма элементов, разумеется, равна 21. Делим её на 7, получая 3. Теперь из каждого числа исходной последовательности вычтем 3, каждое значение возведем в квадрат, а результаты сложим вместе. Получится 12. Теперь нам остается разделить число на количество элементов, и, казалось бы, всё. Но есть загвоздка! Давайте её обсудим.
Зависимость от количества экспериментов
Оказывается, при расчёте дисперсии в знаменателе может стоять одно из двух чисел: либо N, либо N-1. Здесь N - это число проведенных экспериментов или число элементов в последовательности (что, по сути, одно и то же). От чего это зависит?

Если количество испытаний измеряется сотнями, то мы должны ставить в знаменатель N. Если единицами, то N-1. Границу ученые решили провести достаточно символически: на сегодняшний день она проходит по цифре 30. Если экспериментов мы провели менее 30, то делить сумму будем на N-1, а если более - то на N.
Задача
Давайте вернемся к нашему примеру решения задачи на дисперсию и математическое ожидание. Мы получили промежуточное число 12, которое нужно было разделить на N или N-1. Поскольку экспериментов мы провели 21, что меньше 30, выберем второй вариант. Итак, ответ: дисперсия равна 12 / 2 = 2.
Математическое ожидание
Перейдем ко второму понятию, которое мы обязательно должны рассмотреть данной статье. Математическое ожидание - это результат сложения всех возможных исходов, помноженных на соответствующие вероятности. Важно понимать, что полученное значение, как и результат расчёта дисперсии, получается всего один раз для целой задачи, сколько бы исходов в ней не рассматривалось.

Формула математического ожидания достаточно проста: берем исход, умножаем на его вероятность, прибавляем то же самое для второго, третьего результата и т. д. Всё, связанное с этим понятием, рассчитывается несложно. Например, сумма матожиданий равна матожиданию суммы. Для произведения актуально то же самое. Такие простые операции позволяет с собой выполнять далеко не каждая величина в теории вероятности. Давайте возьмем задачу и посчитаем значение сразу двух изученных нами понятий. Кроме того, мы отвлекались на теорию - пришло время попрактиковаться.
Ещё один пример
Мы провели 50 испытаний и получили 10 видов исходов - цифры от 0 до 9 - появляющихся в различном процентном отношении. Это, соответственно: 2%, 10%, 4%, 14%, 2%,18%, 6%, 16%, 10%, 18%. Напомним, что для получения вероятностей требуется разделить значения в процентах на 100. Таким образом, получим 0,02; 0,1 и т.д. Представим для дисперсии случайной величины и математического ожидания пример решения задачи.
Среднее арифметическое рассчитаем по формуле, которую помним с младшей школы: 50/10 = 5.
Теперь переведем вероятности в количество исходов «в штуках», чтобы было удобнее считать. Получим 1, 5, 2, 7, 1, 9, 3, 8, 5 и 9. Из каждого полученного значения вычтем среднее арифметическое, после чего каждый из полученных результатов возведем в квадрат. Посмотрите, как это сделать, на примере первого элемента: 1 - 5 = (-4). Далее: (-4) * (-4) = 16. Для остальных значений проделайте эти операции самостоятельно. Если вы всё сделали правильно, то после сложения всех вы получите 90.

Продолжим расчёт дисперсии и математического ожидания, разделив 90 на N. Почему мы выбираем N, а не N-1? Правильно, потому что количество проведенных экспериментов превышает 30. Итак: 90/10 = 9. Дисперсию мы получили. Если у вас вышло другое число, не отчаивайтесь. Скорее всего, вы допустили банальную ошибку при расчётах. Перепроверьте написанное, и наверняка всё встанет на свои места.
Наконец, вспомним формулу математического ожидания. Не будем приводить всех расчётов, напишем лишь ответ, с которым вы сможете свериться, закончив все требуемые процедуры. Матожидание будет равно 5,48. Напомним лишь, как осуществлять операции, на примере первых элементов: 0*0,02 + 1*0,1… и так далее. Как видите, мы просто умножаем значение исхода на его вероятность.
Отклонение
Ещё одно понятие, тесно связанное с дисперсией и математическим ожиданием - среднее квадратичное отклонение. Обозначается оно либо латинскими буквами sd, либо греческой строчной «сигмой». Данное понятие показывает, насколько в среднем отклоняются значения от центрального признака. Чтобы найти её значение, требуется рассчитать квадратный корень из дисперсии.

Если вы построите график нормального распределения и захотите увидеть непосредственно на нём квадратичного отклонения, это можно сделать в несколько этапов. Возьмите половину изображения слева или справа от моды (центрального значения), проведите перпендикуляр к горизонтальной оси так, чтобы площади получившихся фигур были равны. Величина отрезка между серединой распределения и получившейся проекцией на горизонтальную ось и будет представлять собой среднее квадратичное отклонение.
Программное обеспечение
Как видно из описаний формул и представленных примеров, расчеты дисперсии и математического ожидания - не самая простая процедура с арифметической точки зрения. Чтобы не тратить время, имеет смысл воспользоваться программой, используемой в высших учебных заведениях - она называется «R». В ней есть функции, позволяющие рассчитывать значения для многих понятий из статистики и теории вероятности.
Например, вы задаете вектор значений. Делается это следующим образом: vector <-c(1,5,2…). Теперь, когда вам потребуется посчитать какие-либо значения для этого вектора, вы пишете функцию и задаете его в качестве аргумента. Для нахождения дисперсии вам нужно будет использовать функцию var. Пример её использования: var(vector). Далее вы просто нажимаете «ввод» и получаете результат.
В заключение
Дисперсия и математическое ожидание - это без которых сложно в дальнейшем что-либо рассчитать. В основном курсе лекций в вузах они рассматриваются уже в первые месяцы изучения предмета. Именно из-за непонимания этих простейших понятий и неумения их рассчитать многие студенты сразу начинают отставать по программе и позже получают плохие отметки по результатам сессии, что лишает их стипендии.
Потренируйтесь хотя бы одну неделю по полчаса в день, решая задания, схожие с представленными в данной статье. Тогда на любой контрольной по теории вероятности вы справитесь с примерами без посторонних подсказок и шпаргалок.
В случае, если совокупность разбита на группы по изучаемому признаку, то для данной совокупности могут быть исчислены следующие виды дисперсии: общая, групповые (внутригрупповые), средняя из групповых (средняя из внутригрупповых), межгрупповая.
Первоначально рассчитывает коэффициент детерминации, который показывает какую часть общей вариации изучаемого признака составляет вариация межгрупповая, т.е. обусловленная группировочным признаком:
Эмпирическое корреляционное отношение характеризует тесноту связи между признаками группировочным (факторным) и результативным.
Эмпирическое корреляционное отношение может принимать значения от 0 до 1.
Для оценки тесноты связи на основе показателя эмпирического корреляционного отношения можно воспользоваться соотношениями Чеддока:
Пример 4. Имеются следующие данные о выполнении работ проектно-изыскательскими организациями разной формы собственности:
Определить:
1) общую дисперсию;
2) групповые дисперсии;
3) среднюю из групповых дисперсий;
4) межгрупповую дисперсию;
5) общую дисперсию на основе правила сложения дисперсий;
6) коэффициент детерминации и эмпирическое корреляционное отношение.
Сделайте выводы.
Решение:
1. Определим средний объём выполнения работ предприятий двух форм собственности:
Рассчитаем общую дисперсию:
![]()
2. Определим групповые средние:
![]() млн руб.;
млн руб.;
![]() млн руб.
млн руб.
Групповые дисперсии:
![]() ;
;
3. Рассчитаем среднюю из групповых дисперсий:
4. Определим межгрупповую дисперсию:
5. Рассчитаем общую дисперсию на основе правила сложения дисперсий:
6. Определим коэффициент детерминации:
![]() .
.
Таким образом, объём работ, выполненных проектно-изыскательскими организациями на 22% зависит от формы собственности предприятий.
Эмпирическое корреляционное отношение рассчитываем по формуле
![]() .
.
Величина рассчитанного показателя свидетельствует о том, что зависимость объема работ от формы собственности предприятия невелика.
Пример 5. В результате обследования технологической дисциплины производственных участков получены следующие данные:
Определите коэффициент детерминации
Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г . Синтаксис этого выражения имеет следующий вид:
ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.


Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.


Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
![]()
s 2 – дисперсия выборки;
x ср — среднее значение выборки;
n — размер выборки (количество значений данных),
(x i – x ср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.

Финальная фаза вычисления дисперсии выглядит так:
![]()
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.

— сумма каждого значения данных после возведения в квадрат,
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.


Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Расчет дисперсии в Excel
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.

Где σ 2 j - внутригрупповая дисперсия j -й группы.
Для не сгруппированных данных
остаточная дисперсия
– мера точности аппроксимации, т.е. приближения линии регрессии к исходным данным:

где y(t) – прогноз по уравнению тренда; y t – исходный ряд динамики; n – количество точек; p – число коэффициентов уравнения регрессии (количество объясняющих переменных).
В этом примере она называется несмещенная оценка дисперсии
.
Пример №1 . Распределение рабочих трех предприятий одного объединения по тарифным разрядам характеризуется следующими данными:
| Тарифный разряд рабочего | Численность рабочих на предприятии | ||
| предприятие 1 | предприятие 2 | предприятие 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
Определить:
1. дисперсию по каждому предприятию (внутригрупповые дисперсии);
2. среднюю из внутригрупповых дисперсий;
3. межгрупповую дисперсию ;
4. общую дисперсию.
Решение.
Прежде чем приступить к решению задачи необходимо выяснить, какой признак является результативным, а какой – факторным. В рассматриваемом примере результативным признаком является «Тарифный разряд», а факторным признаком – «Номер (название) предприятия».
Тогда имеем три группы (предприятия), для которых необходимо рассчитать групповую среднюю и внутригрупповые дисперсии :
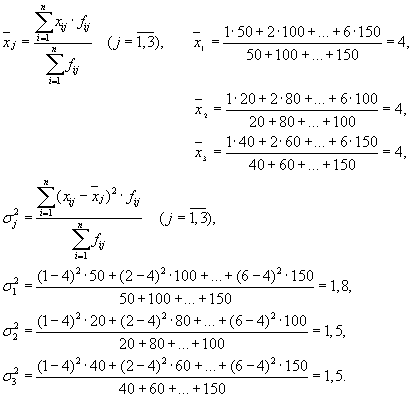
| Предприятие | Групповая средняя, | Внутригрупповая дисперсия, |
| 1 | 4 | 1,8 |
Средняя из внутригрупповых дисперсий (остаточная дисперсия ) рассчитаем по формуле:
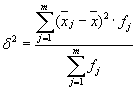
где можно рассчитать:

либо:
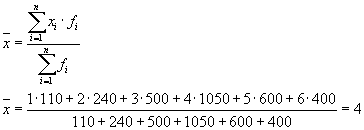
тогда:
Общая дисперсия будет равна: s 2 = 1,6 + 0 = 1,6.
Общую дисперсию также можно рассчитать и по одной из следующих двух формул:
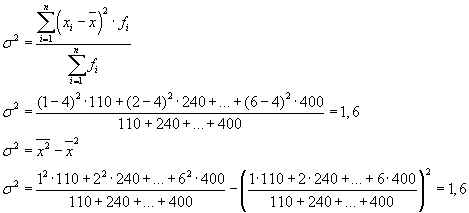
При решении практических задач часто приходится иметь дело с признаком, принимающим только два альтернативных значения. В этом случае говорят не о весе того или иного значения признака, а о его доле в совокупности. Если долю единиц совокупности, обладающих изучаемым признаком, обозначить через «р
», а не обладающих – через «q
», то дисперсию можно рассчитать по формуле:
s 2 = p×q
Пример №2 . По данным о выработке шести рабочих бригады определить межгрупповую дисперсию и оценить влияние рабочей смены на их производительность труда, если общая дисперсия равна 12,2 .
| № рабочего бригады | Выработка рабочего, шт. | |
| в I смену | во II смену | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
Решение . Исходные данные
| X | f 1 | f 2 | f 3 | f 4 | f 5 | f 6 | Итого |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| Итого | 31 | 33 | 37 | 37 | 40 | 38 |
Тогда имеем 6 группы, для которых необходимо рассчитать групповую среднюю и внутригрупповые дисперсии.
1. Находим средние значения каждой группы .
2. Находим среднее квадратическое каждой группы .
Результаты расчета сведем в таблицу:
| Номер группы | Групповая средняя | Внутригрупповая дисперсия |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
3. Внутригрупповая дисперсия характеризует изменение (вариацию) изучаемого (результативного) признака в пределах группы под действием на него всех факторов, кроме фактора, положенного в основание группировки:
Среднюю из внутригрупповых дисперсий рассчитаем по формуле:
4. Межгрупповая дисперсия характеризует изменение (вариацию) изучаемого (результативного) признака под действием на него фактора (факторного признака), положенного в основание группировки.
Межгрупповую дисперсию определим как:
где
Тогда
Общая дисперсия характеризует изменение (вариацию) изучаемого (результативного) признака под действием на него всех без исключения факторов (факторных признаков). По условию задачи она равна 12.2 .
Эмпирическое корреляционное отношение измеряет, какую часть общей колеблемости результативного признака вызывает изучаемый фактор. Это отношение факторной дисперсии к общей дисперсии:
Определяем эмпирическое корреляционное отношение:
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0.3 0.5 0.7 0.9 В нашем примере связь между признаком Y фактором X слабая
Коэффициент детерминации.
Определим коэффициент детерминации:
Таким образом, на 0.67% вариация обусловлена различиями между признаками, а на 99.37% – другими факторами.
Вывод : в данном случае выработка рабочих не зависит от работы в конкретную смену, т..е. влияние рабочей смены на их производительность труда не значительное и обусловлено другими факторами.
Пример №3 . На основе данных о средней заработной плате и квадратах отклонений от её величины по двум группам рабочих найти общую дисперсию, применив правило сложения дисперсий:
Решение:Средняя из внутригрупповых дисперсий
Межгрупповую дисперсию определим как:
Общая дисперсия будет равна: 480 + 13824 = 14304