Найти доверительный интервал для. Доверительный интервал
Одним из методов решения статистических задач является вычисление доверительного интервала. Он используется, как более предпочтительная альтернатива точечной оценке при небольшом объеме выборки. Нужно отметить, что сам процесс вычисления доверительного интервала довольно сложный. Но инструменты программы Эксель позволяют несколько упростить его. Давайте узнаем, как это выполняется на практике.
Этот метод используется при интервальной оценке различных статистических величин. Главная задача данного расчета – избавится от неопределенностей точечной оценки.
В Экселе существуют два основных варианта произвести вычисления с помощью данного метода: когда дисперсия известна, и когда она неизвестна. В первом случае для вычислений применяется функция ДОВЕРИТ.НОРМ , а во втором — ДОВЕРИТ.СТЮДЕНТ .
Способ 1: функция ДОВЕРИТ.НОРМ
Оператор ДОВЕРИТ.НОРМ , относящийся к статистической группе функций, впервые появился в Excel 2010. В более ранних версиях этой программы используется его аналог ДОВЕРИТ . Задачей этого оператора является расчет доверительного интервала с нормальным распределением для средней генеральной совокупности.
Его синтаксис выглядит следующим образом:
ДОВЕРИТ.НОРМ(альфа;стандартное_откл;размер)
«Альфа» — аргумент, указывающий на уровень значимости, который применяется для расчета доверительного уровня. Доверительный уровень равняется следующему выражению:
(1-«Альфа»)*100
«Стандартное отклонение» — это аргумент, суть которого понятна из наименования. Это стандартное отклонение предлагаемой выборки.
«Размер» — аргумент, определяющий величину выборки.
Все аргументы данного оператора являются обязательными.
Функция ДОВЕРИТ имеет точно такие же аргументы и возможности, что и предыдущая. Её синтаксис таков:
ДОВЕРИТ(альфа;стандартное_откл;размер)
Как видим, различия только в наименовании оператора. Указанная функция в целях совместимости оставлена в Excel 2010 и в более новых версиях в специальной категории «Совместимость» . В версиях же Excel 2007 и ранее она присутствует в основной группе статистических операторов.
Граница доверительного интервала определяется при помощи формулы следующего вида:
X+(-)ДОВЕРИТ.НОРМ
Где X – это среднее выборочное значение, которое расположено посередине выбранного диапазона.
Теперь давайте рассмотрим, как рассчитать доверительный интервал на конкретном примере. Было проведено 12 испытаний, вследствие которых были получены различные результаты, занесенные в таблицу. Это и есть наша совокупность. Стандартное отклонение равно 8. Нам нужно рассчитать доверительный интервал при уровне доверия 97%.
- Выделяем ячейку, куда будет выводиться результат обработки данных. Щелкаем по кнопке «Вставить функцию» .
- Появляется Мастер функций . Переходим в категорию «Статистические» и выделяем наименование «ДОВЕРИТ.НОРМ» . После этого клацаем по кнопке «OK» .
- Открывается окошко аргументов. Его поля закономерно соответствуют наименованиям аргументов.
Устанавливаем курсор в первое поле – «Альфа» . Тут нам следует указать уровень значимости. Как мы помним, уровень доверия у нас равен 97%. В то же время мы говорили, что он рассчитывается таким путем:(1-уровень доверия)/100
То есть, подставив значение, получаем:
Путем нехитрых расчетов узнаем, что аргумент «Альфа» равен 0,03 . Вводим данное значение в поле.
Как известно, по условию стандартное отклонение равно 8 . Поэтому в поле «Стандартное отклонение» просто записываем это число.
В поле «Размер» нужно ввести количество элементов проведенных испытаний. Как мы помним, их 12 . Но чтобы автоматизировать формулу и не редактировать её каждый раз при проведении нового испытания, давайте зададим данное значение не обычным числом, а при помощи оператора СЧЁТ . Итак, устанавливаем курсор в поле «Размер» , а затем кликаем по треугольнику, который размещен слева от строки формул.
Появляется список недавно применяемых функций. Если оператор СЧЁТ применялся вами недавно, то он должен быть в этом списке. В таком случае, нужно просто кликнуть по его наименованию. В обратном же случае, если вы его не обнаружите, то переходите по пункту «Другие функции…» .
- Появляется уже знакомый нам Мастер функций . Опять перемещаемся в группу «Статистические» . Выделяем там наименование «СЧЁТ» . Клацаем по кнопке «OK» .
- Появляется окно аргументов вышеуказанного оператора. Данная функция предназначена для того, чтобы вычислять количество ячеек в указанном диапазоне, которые содержат числовые значения. Синтаксис её следующий:
СЧЁТ(значение1;значение2;…)
Группа аргументов «Значения» представляет собой ссылку на диапазон, в котором нужно рассчитать количество заполненных числовыми данными ячеек. Всего может насчитываться до 255 подобных аргументов, но в нашем случае понадобится лишь один.
Устанавливаем курсор в поле «Значение1» и, зажав левую кнопку мыши, выделяем на листе диапазон, который содержит нашу совокупность. Затем его адрес будет отображен в поле. Клацаем по кнопке «OK» .
- После этого приложение произведет вычисление и выведет результат в ту ячейку, где она находится сама. В нашем конкретном случае формула получилась такого вида:
ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13))
Общий результат вычислений составил 5,011609 .
- Но это ещё не все. Как мы помним, граница доверительного интервала вычисляется путем сложения и вычитания от среднего выборочного значения результата вычисления ДОВЕРИТ.НОРМ
. Таким способом рассчитывается соответственно правая и левая граница доверительного интервала. Само среднее выборочное значение можно рассчитать при помощи оператора СРЗНАЧ
.
Данный оператор предназначен для расчета среднего арифметического значения выбранного диапазона чисел. Он имеет следующий довольно простой синтаксис:
СРЗНАЧ(число1;число2;…)
Аргумент «Число» может быть как отдельным числовым значением, так и ссылкой на ячейки или даже целые диапазоны, которые их содержат.
Итак, выделяем ячейку, в которую будет выводиться расчет среднего значения, и щелкаем по кнопке «Вставить функцию» .
- Открывается Мастер функций . Снова переходим в категорию «Статистические» и выбираем из списка наименование «СРЗНАЧ» . Как всегда, клацаем по кнопке «OK» .
- Запускается окно аргументов. Устанавливаем курсор в поле «Число1» и с зажатой левой кнопкой мыши выделяем весь диапазон значений. После того, как координаты отобразились в поле, клацаем по кнопке «OK» .
- После этого СРЗНАЧ выводит результат расчета в элемент листа.
- Производим расчет правой границы доверительного интервала. Для этого выделяем отдельную ячейку, ставим знак «=»
и складываем содержимое элементов листа, в которых расположены результаты вычислений функций СРЗНАЧ
и ДОВЕРИТ.НОРМ
. Для того, чтобы выполнить расчет, жмем на клавишу Enter
. В нашем случае получилась следующая формула:
Результат вычисления: 6,953276
- Таким же образом производим вычисление левой границы доверительного интервала, только на этот раз от результата вычисления СРЗНАЧ
отнимаем результат вычисления оператора ДОВЕРИТ.НОРМ
. Получается формула для нашего примера следующего типа:
Результат вычисления: -3,06994
- Мы попытались подробно описать все действия по вычислению доверительного интервала, поэтому детально расписали каждую формулу. Но можно все действия соединить в одной формуле. Вычисление правой границы доверительного интервала можно записать так:
СРЗНАЧ(B2:B13)+ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13))
- Аналогичное вычисление левой границы будет выглядеть так:
СРЗНАЧ(B2:B13)-ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13))














Способ 2: функция ДОВЕРИТ.СТЮДЕНТ
Кроме того, в Экселе есть ещё одна функция, которая связана с вычислением доверительного интервала – ДОВЕРИТ.СТЮДЕНТ . Она появилась, только начиная с Excel 2010. Данный оператор выполняет вычисление доверительного интервала генеральной совокупности с использованием распределения Стьюдента. Его очень удобно использовать в том случае, когда дисперсия и, соответственно, стандартное отклонение неизвестны. Синтаксис оператора такой:
ДОВЕРИТ.СТЬЮДЕНТ(альфа;стандартное_откл;размер)
Как видим, наименования операторов и в этом случае остались неизменными.
Посмотрим, как рассчитать границы доверительного интервала с неизвестным стандартным отклонением на примере всё той же совокупности, что мы рассматривали в предыдущем способе. Уровень доверия, как и в прошлый раз, возьмем 97%.
- Выделяем ячейку, в которую будет производиться расчет. Клацаем по кнопке «Вставить функцию» .
- В открывшемся Мастере функций переходим в категорию «Статистические» . Выбираем наименование «ДОВЕРИТ.СТЮДЕНТ» . Клацаем по кнопке «OK» .
- Производится запуск окна аргументов указанного оператора.
В поле «Альфа» , учитывая, что уровень доверия составляет 97%, записываем число 0,03 . Второй раз на принципах расчета данного параметра останавливаться не будем.
После этого устанавливаем курсор в поле «Стандартное отклонение» . На этот раз данный показатель нам неизвестен и его требуется рассчитать. Делается это при помощи специальной функции – СТАНДОТКЛОН.В . Чтобы вызвать окно данного оператора, кликаем по треугольнику слева от строки формул. Если в открывшемся списке не находим нужного наименования, то переходим по пункту «Другие функции…» .
- Запускается Мастер функций . Перемещаемся в категорию «Статистические» и отмечаем в ней наименование «СТАНДОТКЛОН.В» . Затем клацаем по кнопке «OK» .
- Открывается окно аргументов. Задачей оператора СТАНДОТКЛОН.В
является определение стандартного отклонения при выборке. Его синтаксис выглядит так:
СТАНДОТКЛОН.В(число1;число2;…)
Нетрудно догадаться, что аргумент «Число» — это адрес элемента выборки. Если выборка размещена единым массивом, то можно, использовав только один аргумент, дать ссылку на данный диапазон.
Устанавливаем курсор в поле «Число1» и, как всегда, зажав левую кнопку мыши, выделяем совокупность. После того, как координаты попали в поле, не спешим жать на кнопку «OK» , так как результат получится некорректным. Прежде нам нужно вернуться к окну аргументов оператора ДОВЕРИТ.СТЮДЕНТ , чтобы внести последний аргумент. Для этого кликаем по соответствующему наименованию в строке формул.
- Снова открывается окно аргументов уже знакомой функции. Устанавливаем курсор в поле «Размер» . Опять жмем на уже знакомый нам треугольник для перехода к выбору операторов. Как вы поняли, нам нужно наименование «СЧЁТ» . Так как мы использовали данную функцию при вычислениях в предыдущем способе, в данном списке она присутствует, так что просто щелкаем по ней. Если же вы её не обнаружите, то действуйте по алгоритму, описанному в первом способе.
- Попав в окно аргументов СЧЁТ , ставим курсор в поле «Число1» и с зажатой кнопкой мыши выделяем совокупность. Затем клацаем по кнопке «OK» .
- После этого программа производит расчет и выводит значение доверительного интервала.
- Для определения границ нам опять нужно будет рассчитать среднее значение выборки. Но, учитывая то, что алгоритм расчета при помощи формулы СРЗНАЧ тот же, что и в предыдущем способе, и даже результат не изменился, не будем на этом подробно останавливаться второй раз.
- Сложив результаты вычисления СРЗНАЧ и ДОВЕРИТ.СТЮДЕНТ , получаем правую границу доверительного интервала.
- Отняв от результатов расчета оператора СРЗНАЧ результат расчета ДОВЕРИТ.СТЮДЕНТ , имеем левую границу доверительного интервала.
- Если расчет записать одной формулой, то вычисление правой границы в нашем случае будет выглядеть так:
СРЗНАЧ(B2:B13)+ДОВЕРИТ.СТЬЮДЕНТ(0,03;СТАНДОТКЛОН.В(B2:B13);СЧЁТ(B2:B13))
- Соответственно, формула расчета левой границы будет выглядеть так:
СРЗНАЧ(B2:B13)-ДОВЕРИТ.СТЬЮДЕНТ(0,03;СТАНДОТКЛОН.В(B2:B13);СЧЁТ(B2:B13))













Как видим, инструменты программы Excel позволяют существенно облегчить вычисление доверительного интервала и его границ. Для этих целей используются отдельные операторы для выборок, у которых дисперсия известна и неизвестна.
Оценка доверительных интервалов
Цели обучения
Статистика рассматривает следующие две основные задачи :
У нас есть некоторая оценка, построенная на выборочных данных, и мы хотим сделать некоторое вероятностное утверждение относительно того, где находится истинное значение оцениваемого параметра.
У нас есть конкретная гипотеза, которую необходимо проверить на основе выборочных данных.
В данной теме мы рассматриваем первую задачу. Введем также определение доверительного интервала.
Доверительный интервал - это интервал, который строится вокруг оценочного значения параметра и показывает, где находится истинное значение оцениваемого параметра с априори заданной вероятностью.
Изучив материал данной темы, Вы:
узнаете, что такое доверительный интервал оценки;
научитесь классифицировать статистические задачи;
освоите технику построения доверительных интервалов, как по статистическим формулам, так и с помощью программного инструментария;
научитесь определять необходимые размеры выборок для достижения определенных параметров точности статистических оценок.
Распределения выборочных характеристик
Т-распределение
Как обсуждали выше распределение случайной величины близко к стандартизованному нормальному распределению с параметрами 0 и 1. Поскольку нам не известна величина σ, мы заменяем ее на некоторую оценку s . Величина уже имеет другое распределение, а именно или Распределение Стьюдента , которое определяется параметром n -1 (число степеней свободы). Это распределение близко к нормальному распределению (чем больше n , тем распределения ближе).
На рис. 95  представлено распределение Стьюдента с 30 степенями свободы. Как видно, оно весьма близко к нормальному распределению.
представлено распределение Стьюдента с 30 степенями свободы. Как видно, оно весьма близко к нормальному распределению.
Аналогично функциям для работы с нормальным распределением НОРМРАСП
и НОРМОБР
имеются функции для работы с t-распределением - СТЬЮДРАСП (TDIST)
и СТЬЮДРАСПОБР (TINV)
. Пример использования этих функций можно посмотреть в файле СТЬЮДРАСП.XLS (шаблон
и решение
) и на рис. 96  .
.
Распределения других характеристик
Как мы уже знаем, для определения точности оценивания математического ожидания нам необходимо t-распределение. Для оценивания других параметров, например, дисперсии, требуются другие распределения. Два из них - это F-распределение и x 2 -распределение .
Доверительный интервал для среднего значения
Доверительный интервал - это интервал, который строится вокруг оценочного значения параметра и показывает, где находится истинное значение оцениваемого параметра с априори заданной вероятностью.
Построение доверительного интервала для среднего значения происходит следующим образом :
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом планирует выбрать 40 посетителей из тех, кто уже попробовал его и предложить им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемое количество баллов, которое получит новый продукт и построить 95%-й доверительный интервал этой оценки. Как это осуществить? (см. файл СЭНДВИЧ1.XLS (шаблон и решение ).
Решение
Для решения данной задачи можно воспользоваться . Результаты представлены на рис. 97  .
.
Доверительный интервал для суммарного значения
Иногда по выборочным данным требуется оценить не математическое ожидание, а общую сумму значений. Например, в ситуации с аудитором интерес может представлять оценка не средней величины счета, а суммы всех счетов.
Пусть N
- общее количество элементов, n
- размер выборки, T 3
- сумма значений в выборке, T" - оценка для суммы по всей совокупности, тогда ![]() , а доверительный интервал вычисляется по формуле , где s - оценка стандартного отклонения для выборки, - оценка среднего для выборки.
, а доверительный интервал вычисляется по формуле , где s - оценка стандартного отклонения для выборки, - оценка среднего для выборки.
Пример
Допустим, некоторая налоговая служба хочет оценить размер суммарных налоговых возвратов для 10 000 налогоплательщиков. Налогоплательщик либо получает возврат, либо доплачивает налоги. Найдите 95%-й доверительный интервал для суммы возврата при условии, что размер выборки составляет 500 человек (см. файл СУММА ВОЗВРАТОВ.XLS (шаблон и решение ).
Решение
В StatPro
нет специальной процедуры для этого случая, однако можно заметить, что границы можно получить из границ для среднего исходя из вышеприведенных формул (рис. 98  ).
).
Доверительный интервал для пропорции
Пусть p - математическое ожидание доли клиентов, а р в
- оценка этой доли, полученная по выборке размера n. Можно показать, что для достаточно больших  распределение оценки будет близко к нормальному с математическим ожиданием p
и стандартным отклонением
распределение оценки будет близко к нормальному с математическим ожиданием p
и стандартным отклонением ![]() . Стандартная ошибка оценки в данном случае выражается как
. Стандартная ошибка оценки в данном случае выражается как  , а доверительный интервал как
, а доверительный интервал как  .
.
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом выбрал 40 посетителей из тех, кто уже попробовал его и предложил им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемую долю клиентов, которые оценивают новый продукт не менее чем в 6 баллов (он ожидает, что именно эти клиенты и будут потребителями нового продукта).
Решение
Первоначально создаем новый столбец по признаку 1, если оценка клиента была больше 6 баллов и 0 иначе (см. файл СЭНДВИЧ2.XLS (шаблон и решение ).
Способ 1
Подсчитывая количество 1, оцениваем долю, а далее используем формулы.
Значение z кр берется из специальных таблиц нормального распределения (например, 1,96 для 95%-го доверительного интервала).
Используя данный подход и конкретные данные для построения 95%-го интервала, получим следующие результаты (рис. 99  ). Критическое значение параметра z кр
равно 1,96. Стандартная ошибка оценки - 0,077. Нижняя граница доверительного интервала - 0,475. Верхняя граница доверительного интервала - 0,775. Таким образом, менеджер вправе полагать с 95%-й долей уверенности, что процент клиентов, оценивших новый продукт на 6 баллов и выше, будет между 47,5 и 77,5.
). Критическое значение параметра z кр
равно 1,96. Стандартная ошибка оценки - 0,077. Нижняя граница доверительного интервала - 0,475. Верхняя граница доверительного интервала - 0,775. Таким образом, менеджер вправе полагать с 95%-й долей уверенности, что процент клиентов, оценивших новый продукт на 6 баллов и выше, будет между 47,5 и 77,5.
Способ 2
Данная задача допускает решение стандартными средствами StatPro . Для этого достаточно заметить, что доля в данном случае совпадает со средним значением столбца Тип . Далее применим StatPro/Statistical Inference/One-Sample Analysis для построения доверительного интервала среднего значения (оценки математического ожидания) для столбца Тип . Полученные в этом случае результат, будут весьма близок к результату 1-го способа (рис. 99).
Доверительный интервал для стандартного отклонения
В качестве оценки стандартного отклонения используется s (формула приведена в разделе 1). Функцией плотности распределения оценки s является функция хи-квадрат , которая, как и t-распределение, имеет n-1 степень свободы. Имеются специальные функции для работы с этим распределением ХИ2РАСП (CHIDIST) и ХИ2ОБР (CHIINV) .
Доверительный интервал в этом случае уже будет не симметричным. Условная схема границ представлена на рис. 100 .
Пример
Станок должен производить детали диаметром 10 см. Однако в силу различных обстоятельств происходят ошибки. Контролера по качеству волнуют два обстоятельства: во-первых, среднее значение должно равняться 10 см; во-вторых, даже в этом случае, если отклонения будут велики, то многие детали будут забракованы. Ежедневно он делает выборку из 50 деталей (см. файл КОНТРОЛЬ КАЧЕСТВА.XLS (шаблон и решение ). Какие выводы может дать такая выборка?
Решение
Построим 95%-й доверительные интервалы для среднего и для стандартного отклонения с помощью StatPro/Statistical Inference/ One-Sample Analysis
(рис. 101  ).
).
Далее, используя предположение о нормальном распределении диаметров, рассчитаем долю бракованных изделий, задавшись предельным отклонением 0,065. Используя возможности таблицы подстановки (случай двух параметров), построим зависимость доли брака от среднего значения и стандартного отклонения (рис. 102  ).
).
Доверительный интервал для разности двух средних значений
Это одно из наиболее важных применений статистических методов. Примеры ситуаций.
Менеджер магазина одежды хотел бы знать, на сколько больше или меньше тратит в магазине средняя женщина-покупатель, чем мужчина.
Две авиакомпании летают аналогичными маршрутами. Организация-потребитель хотела бы сравнить разницу между среднеожидаемыми временами задержек рейсов по обеим авиакомпаниям.
Компания рассылает купоны на отдельные виды товаров в одном городе и не рассылает в другом. Менеджеры хотят сравнить средние объемы покупок этих товаров в ближайшие два месяца.
Автомобильный дилер часто имеет дело на презентациях с замужними парами. Чтобы понять их персональную реакцию на презентацию, пары часто опрашивают отдельно. Менеджер хочет оценить разницу в рейтингах указываемых мужчинами и женщинами.
Случай независимых выборок
Разность средних значений будет иметь t-распределение с n 1 + n 2 - 2 степенями свободы. Доверительный интервал для μ 1 - μ 2 выражается соотношением:

Данная задача допускает решение не только по вышеприведенным формулам, но и стандартными средствами StatPro . Для этого достаточно применить
Доверительный интервал для разности между пропорциями
Пусть - математическое ожидание долей. Пусть - их выборочные оценки, построенные по выборкам размера n 1 и n 2 соответственно. Тогда является оценкой для разности . Следовательно, доверительный интервал этой разности выражается как:
Здесь z кр является значением, полученным из нормального распределения по специальным таблицам (например, 1,96 для 95%-й доверительного интервала).
Стандартная ошибка оценки выражается в данном случае соотношением:
 .
.
Пример
Магазин, готовясь к большой распродаже, предпринял следующие маркетинговые исследования. Были выбраны 300 лучших покупателей, которые в свою очередь были случайным образом поделены на две группы по 150 членов в каждой. Всем из отобранных покупателей были разосланы приглашения для участия в распродаже, но только для членов первой группы был приложен купон, дающий право на скидку 5%. В ходе распродажи покупки всех 300 отобранных покупателей фиксировались. Каким образом менеджер может интерпретировать полученные результаты и сделать заключение об эффективности предоставления купонов? (см. файл КУПОНЫ.XLS (шаблон и решение )).
Решение
Для нашего конкретного случая из 150 покупателей, получивших купон на скидку, 55 сделали покупку на распродаже, а среди 150, не получивших купон, покупку сделали только 35 (рис. 103  ). Тогда значения выборочных пропорций соответственно 0,3667 и 0,2333. А выборочная разность между ними равна соответственно 0,1333. Полагая доверительный интервал 95%-м, находим по таблице нормального распределения z кр
= 1,96. Вычисление стандартной ошибки выборочной разности равно 0,0524. Окончательно получаем, что нижняя граница 95%-го доверительного интервала равна 0,0307, а верхняя граница 0,2359 соответственно. Полученные результаты можно интерпретировать таким образом, что на каждых 100 покупателей, получивших купон со скидкой, можно ожидать от 3 до 23 новых покупателей. Однако надо иметь в виду, что этот вывод сам по себе еще не означает эффективности применения купонов (поскольку, предоставляя скидку, мы теряем в прибыли!). Продемонстрируем это на конкретных данных. Предположим, что средний размер покупки равен 400 руб., из которых 50 руб. есть прибыль магазина. Тогда ожидаемая прибыль на 100 покупателях, не получивших купон, равна:
). Тогда значения выборочных пропорций соответственно 0,3667 и 0,2333. А выборочная разность между ними равна соответственно 0,1333. Полагая доверительный интервал 95%-м, находим по таблице нормального распределения z кр
= 1,96. Вычисление стандартной ошибки выборочной разности равно 0,0524. Окончательно получаем, что нижняя граница 95%-го доверительного интервала равна 0,0307, а верхняя граница 0,2359 соответственно. Полученные результаты можно интерпретировать таким образом, что на каждых 100 покупателей, получивших купон со скидкой, можно ожидать от 3 до 23 новых покупателей. Однако надо иметь в виду, что этот вывод сам по себе еще не означает эффективности применения купонов (поскольку, предоставляя скидку, мы теряем в прибыли!). Продемонстрируем это на конкретных данных. Предположим, что средний размер покупки равен 400 руб., из которых 50 руб. есть прибыль магазина. Тогда ожидаемая прибыль на 100 покупателях, не получивших купон, равна:
50 0,2333 100 = 1166,50 руб.
Аналогичные вычисления для 100 покупателей получивших купон, дают:
30 0,3667 100 = 1100,10 руб.
Уменьшение средней прибыли до 30 объясняется тем, что, используя скидку, покупатели, получившие купон, в среднем будут делать покупку на 380 руб.
Таким образом, итоговый вывод говорит о неэффективности использования таких купонов в данной конкретной ситуации.
Замечание. Данная задача допускает решение стандартными средствами StatPro . Для этого достаточно свести данную задачу к задаче оценки разности двух средних способом, а далее применить StatPro/Statistical Inference/Two-Sample Analysis для построения доверительного интервала разности двух средних значений.
Управление длиной доверительного интервала
Длина доверительного интервала зависит от следующих условий :
непосредственно данных (стандартное отклонение);
уровня значимости;
размера выборки.
Размер выборки для оценки среднего значения
Сначала рассмотрим задачу в общем случае. Обозначим данное нам значение половины длины доверительного интервала за В
(рис. 104  ). Нам известно, что доверительный интервал для среднего значения некоторой случайной величины X
выражается как
). Нам известно, что доверительный интервал для среднего значения некоторой случайной величины X
выражается как ![]() , где
, где ![]() . Полагая:
. Полагая:
![]() и выражая n
, получим .
и выражая n
, получим .
К сожалению, точное значение дисперсии случайной величины X нам не известно. Кроме этого, нам неизвестно и значение t кр , так как оно зависит от n через количество степеней свободы. В данной ситуации мы можем поступить следующим образом. Вместо дисперсии s используем какую-либо оценку дисперсии, по каким-либо имеющимся реализациям исследуемой случайной величины. Вместо значения t кр используем значение z кр для нормального распределения. Это вполне допустимо, поскольку функции плотности распределений для нормального и t-распределения очень близки (за исключением случая малых n ). Таким образом, искомая формула принимает вид:
 .
.
Поскольку формула дает, вообще говоря, нецелочисленные результат, в качестве искомого размера выборки берется округление с избытком результата.
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом планирует выбрать некоторое количество посетителей из тех, кто уже попробовал его, и предложить им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемое количество баллов, которое получит новый продукт и построить 95%-й доверительный интервал этой оценки. При этом он хочет, чтобы половина ширины доверительного интервала не превышала 0,3. Какое количество посетителей ему необходимо опросить?
выглядит следующим образом:

Здесь р оц - оценка доли p , а В есть заданная половина длины доверительного интервала. Завышенное значение для n можно получить, используя значение р оц = 0,5. В этом случае длина доверительного интервала не будет превосходить заданного значения В при любом истинном значении p .
Пример
Пусть менеджер из предыдущего примера планирует оценить долю клиентов, отдавших предпочтение новому виду продукции. Он хочет построить 90%-й доверительный интервал, половина длины которого не превосходила бы 0,05. Сколько клиентов должно войти в случайную выборку?
Решение
В нашем случае значение z кр
= 1,645. Поэтому искомое количество вычисляется как  .
.
Если бы менеджер имел основания полагать, что искомое значение p составляет, например, примерно 0,3, то, подставляя это значение в вышеприведенную формулу, мы получили бы меньшее значение величины случайной выборки, а именно 228.
Формула для определения размеров случайной выборки в случае разности между двумя средними значениями записывается как:
 .
.
Пример
Некоторая компьютерная компания имеет сервисный центр по обслуживанию клиентов. В последнее время увеличилось количество жалоб клиентов на плохое качество обслуживания. В сервисном центре в основном работают сотрудники двух типов: не имеющие большого опыта, но закончившие специальные подготовительные курсы, и имеющие большой практический опыт, но не закончившие специальных курсов. Компания хочет проанализировать нарекания клиентов за последние полгода и сравнить их средние количества, приходящиеся на каждую из двух групп сотрудников. Предполагается, что количества в выборках по обеим группам будут одинаковые. Какое количество сотрудников необходимо включить в выборку, чтобы получить 95%-й интервал с половиной длины не более 2?
Решение
Здесь σ оц есть оценка стандартного отклонения обеих случайных переменных в предположении, что они близки. Таким образом, в нашей задаче нам необходимо каким-то образом получить эту оценку. Это можно сделать, например, следующим образом. Просмотрев данные по нареканиям клиентов за последние полгода, менеджер может заметить, что на каждого сотрудника в основном приходится от 6 до 36 нареканий. Зная, что для нормального распределения практически все значения удалены от среднего значения не более чем на три стандартных отклонения, он может с определенным основанием полагать, что:
![]() , откуда σ оц
= 5.
, откуда σ оц
= 5.
Подставляя это значение в формулу, получаем  .
.
Формула для определения размера случайной выборки в случае оценки разности между долями имеет вид:

Пример
Некоторая компания имеет две фабрики по производству аналогичной продукции. Менеджер компании хочет сравнить доли бракованной продукции на обеих фабриках. По имеющейся информации процент брака на обеих фабриках составляет от 3 до 5%. Предполагается построить 99%-й доверительный интервал с половиной длины не более 0,005 (или 0,5%). Какое количество изделий необходимо отобрать с каждой фабрики?
Решение
Здесь р 1оц и р 2оц являются оценками двух неизвестных долей брака на 1-й и 2-й фабрике. Если положить р 1оц = р 2оц = 0,5, то мы получим завышенное значение для n . Но поскольку в нашем случае мы имеем некоторую априорную информацию об этих долях, то мы берем верхнюю оценку этих долей, а именно 0,05. Получаем
Когда делается оценка некоторых параметров совокупности по выборочным данным, полезно дать не только точечную оценку параметра, но и указать доверительный интервал, который показывает, где может находиться точное значение оцениваемого параметра.
В данной главе мы также познакомились с количественными соотношениями, позволяющими строить такие интервалы для различных параметров; узнали способы управления длиной доверительного интервала.
Отметим также, что задачу оценки размеров выборки (задача планирования эксперимента) можно решить, используя стандартные средства StatPro , а именно StatPro/Statistical Inference/Sample Size Selection .
Цель – научить студентов алгоритмам вычисления доверительных интервалов статистических параметров.
При статистической обработке данных вычисленные средняя арифметическая, коэффициент вариации, коэффициент корреляции, критерии различия и другие точечные статистики должны получить количественные границы доверия, которые обозначают возможные колебания показателя в меньшую и большую стороны в пределах доверительного интервала.
Пример
3.1
.
Распределение
кальция в сыворотке крови обезьян, как
было установлено ранее, характеризуется
следующими выборочными показателями:
=
11,94 мг%; =
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней (
=
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней ( )
при доверительной вероятностиP
= 0,95.
)
при доверительной вероятностиP
= 0,95.
Генеральная средняя находится с определенной вероятностью в интервале:
 ,
где
,
где
 –
выборочная средняя арифметическая;t
– критерий Стьюдента;
–
выборочная средняя арифметическая;t
– критерий Стьюдента;
 –
ошибка средней арифметической.
–
ошибка средней арифметической.
По
таблице «Значения критерия Стьюдента»
находим значение
 при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
или
11,69
 12,19
12,19
Таким образом, с вероятностью 95%, можно утверждать, что генеральная средняя данного нормального распределения находится между 11,69 и 12,19 мг%.
Пример
3.2
. Определите
границы 95%-ного доверительного интервала
для генеральной дисперсии ( )
распределения кальция в крови обезьян,
если известно, что
)
распределения кальция в крови обезьян,
если известно, что =
1,60, приn
= 100.
=
1,60, приn
= 100.
Для решения задачи можно воспользоваться следующей формулой:
Где
 –
статистическая ошибка дисперсии.
–
статистическая ошибка дисперсии.
Находим
ошибку выборочной дисперсии по формуле:
 .
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
.
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
Воспользуемся формулой и получим:
или
1,38
 1,82
1,82
Более
точно доверительный интервал генеральной
дисперсии можно построить с применением
 (хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия
(хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле
для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле ,
для верхней –
,
для верхней – .
Например, для доверительного уровня
.
Например, для доверительного уровня =
0,99
=
0,99 = 0,010,
= 0,010, =
0,990. Соответственно по таблице распределения
критических значений
=
0,990. Соответственно по таблице распределения
критических значений ,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
 и
и .
Получаем
.
Получаем равно 135,80, а
равно 135,80, а равно70,06.
равно70,06.
Чтобы
найти доверительные границы генеральной
дисперсии с помощью
 воспользуемся
формулами: для нижней границы
воспользуемся
формулами: для нижней границы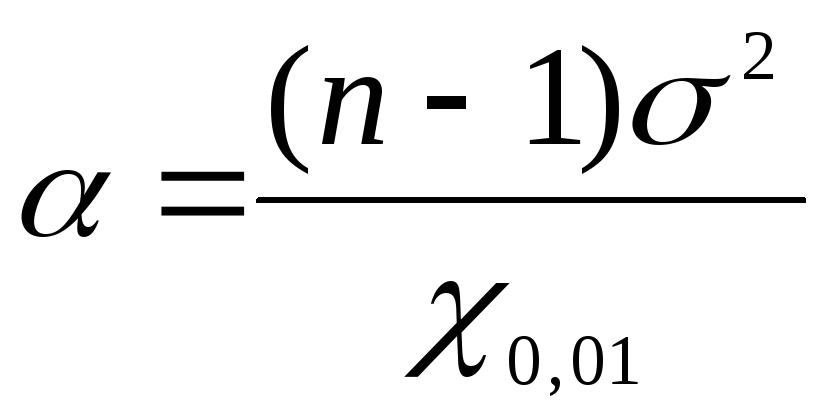 ,
для верхней границы
,
для верхней границы .
Подставим данные задачи найденные
значения
.
Подставим данные задачи найденные
значения в
формулы:
в
формулы: =
1,17;
=
1,17; =
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
=
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
Пример 3.3 . Среди 1000 семян пшеницы из поступившей на элеватор партии обнаружено 120 семян зараженных спорыньей. Необходимо определить вероятные границы генеральной доли зараженных семян в данной партии пшеницы.
Доверительные границы для генеральной доли при всех возможных ее значениях целесообразно определять по формуле:
 ,
,
Где n – число наблюдений; m – абсолютная численность одной из групп; t – нормированное отклонение.
Выборочная
доля зараженных семян равна
 или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
 )t
= 1,960.
)t
= 1,960.
Подставляем имеющиеся данные в формулу:
Отсюда
границы доверительного интервала
равны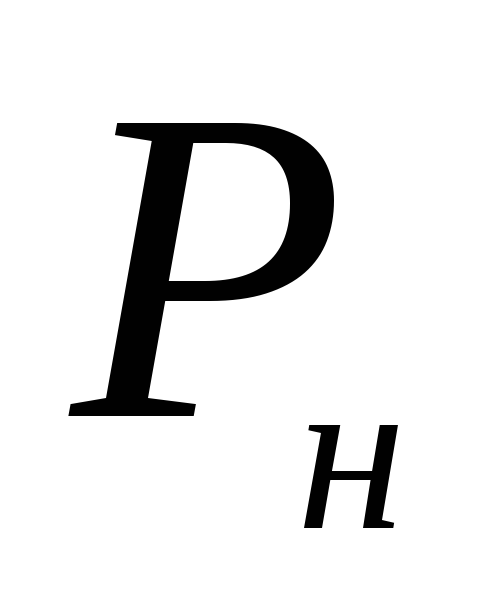 =
0,122–0,041 = 0,081, или 8,1%;
=
0,122–0,041 = 0,081, или 8,1%; = 0,122 + 0,041 = 0,163, или 16,3%.
= 0,122 + 0,041 = 0,163, или 16,3%.
Таким образом, с доверительной вероятностью 95% можно утверждать, что генеральная доля зараженных семян находится между 8,1 и 16,3%.
Пример 3.4 . Коэффициент вариации, характеризующий варьирование кальция (мг%) в сыворотке крови обезьян, оказался равным 10,6%. Объем выборки n = 100. Необходимо определить границы 95%-ного доверительного интервала для генерального параметра Cv .
Границы доверительного интервала для генерального коэффициента вариации Cv определяются по следующим формулам:
 и
и
 ,
гдеK
промежуточная
величина, вычисляемая по формуле
,
гдеK
промежуточная
величина, вычисляемая по формуле
 .
.
Зная,
что при доверительной вероятности Р
= 95% нормированное отклонение (критерий
Стьюдента при k
=
 )t
= 1,960,
предварительно рассчитаем величину К:
)t
= 1,960,
предварительно рассчитаем величину К:
 .
.
 или
9,3%
или
9,3%
 или
12,3%
или
12,3%
Таким образом, генеральный коэффициент вариации с доверительной вероятностью 95% лежит в интервале от 9,3 до 12,3%. При повторных выборках коэффициент вариации не превысит 12,3% и не окажется ниже 9,3% в 95 случаях из 100.
Вопросы для самоконтроля:

Задачи для самостоятельного решения.
1. Средний процент жира в молоке за лактацию коров холмогорских помесей был следующим: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3,8. Установите доверительные интервалы для генеральной средней при доверительной вероятности 95% (20 баллов).
2. На 400 растениях гибридной ржи первые цветки появились в среднем на 70,5 день после посева. Среднее квадратическое отклонение было 6,9 дня. Определите ошибку средней и доверительные интервалы для генеральной средней и дисперсии при уровне значимости W = 0,05 и W = 0,01 (25 баллов).
3.
При изучении длины листьев 502 экземпляров
садовой земляники были получены следующие
данные:
 = 7,86 см; σ
= 1,32 см,
= 7,86 см; σ
= 1,32 см,
 =± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
=± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
4. При обследовании 150 взрослых мужчин средний рост был равен 167 см, а σ = 6 см. В каких пределах находится генеральная средняя и генеральная дисперсия с доверительной вероятностью 0,99 и 0,95? (25 баллов).
5.
Распределение кальция в сыворотке крови
обезьян характеризуется следующими
выборочными показателями:
 = 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
= 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
6. Было изучено общее содержание азота в плазме крови крыс-альбиносов в возрасте 37 и 180 дней. Результаты выражены в граммах на 100 см 3 плазмы. В возрасте 37 дней 9 крыс имели: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. В возрасте 180 дней 8 крыс имели: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1,12. Установите доверительные интервалы для разницы с доверительной вероятностью 0,95 (50 баллов).
7. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения кальция (мг%) в сыворотке крови обезьян, если для этого распределения объем выборки n = 100, статистическая ошибка выборочной дисперсии s σ 2 = 1,60 (40 баллов).
8. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения 40 колосков пшеницы по длине (σ 2 = 40, 87 мм 2). (25 баллов).
9. Курение считают основным фактором, предрасполагающим к обструктивным заболеваниям легких. Пассивное курение таким фактором не считается. Ученые усомнились в безвредности пассивного курения и исследовали проходимость дыхательных путей у некурящих, пассивных и активных курильщиков. Для характеристики состояния дыхательных путей взяли один из показателей функции внешнего дыхания – максимальную объемную скорость середины выдоха. Уменьшение этого показателя – признак нарушения проходимости дыхательных путей. Данные обследования приведены в таблице.
|
Число обследованных |
Максимальная объемная скорость середины выдоха, л/с |
||
|
Стандартное отклонение |
|||
|
Некурящие |
|||
|
работают в помещении, где не курят | |||
|
работают в накуренном помещении | |||
|
Курящие |
|||
|
выкуривающие небольшое число сигарет | |||
|
выкуривающие среднее число сигарет | |||
|
выкуривающие большое число сигарет | |||
По данным таблицы найдите 95% доверительные интервалы для генеральной средней и генеральной дисперсии для каждой из групп. В чем заключаются различия между группами? Результаты представьте графически (25 баллов).
10. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной дисперсии численности поросят в 64 опоросах, если статистическая ошибка выборочной дисперсии s σ 2 = 8, 25 (30 баллов).
11. Известно, что средняя масса кроликов составляет 2,1 кг. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной средней и дисперсии при n = 30, σ = 0,56 кг (25 баллов).
12.
У 100 колосьев измеряли озерненность
колоса (Х
),
длину колоса (Y
)
и массу зерна в колосе (Z
).
Найти доверительные интервалы для
генеральной средней и дисперсии при P
1
= 0,95, P
2
= 0,99, P
3
= 0,999, если
 = 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
= 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
13.
В отобранных случайным образом 100
колосьях озимой пшеницы подсчитывалось
число колосков. Выборочная совокупность
характеризовалась следующими показателями:
 = 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат (
= 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат ( )
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
)
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
14. Число ребер на раковинах ископаемого моллюска Orthambonites calligramma :
Известно, что n = 19, σ = 4,25. Определите границы доверительного интервала для генеральной средней и генеральной дисперсии при уровне значимости W = 0,01 (25 баллов).
15. Для определения удоев молока на молочно-товарной ферме ежедневно определялась продуктивность 15 коров. По данным за год каждая корова давала в среднем в сутки следующее количество молока (л): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Постройте доверительные интервалы для генеральной дисперсии и средней арифметической. Можно ли ожидать, что среднегодовой удой на каждую корову составит 10000 литров? (50 баллов).
16. С целью определения урожая пшеницы в среднем по агрохозяйству были проведены укосы на пробных участках площадью 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 и 2 га. Урожайность (ц/га) с участков составила 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 соответственно. Постройте доверительные интервалы для генеральных дисперсии и средней арифметической. Можно ли ожидать, что в среднем по агрохозяйству урожай составит 42 ц/га? (50 баллов).
Доверительные интервалы.
Вычисление доверительного интервала базируется на средней ошибке соответствующего параметра. Доверительный интервал показывает, в каких пределах с вероятностью (1-a) находится истинное значение оцениваемого параметра. Здесь a – уровень значимости, (1-a) называют также доверительной вероятностью.
В первой главе мы показали, что, например, для среднего арифметического, истинное среднее по совокупности примерно в 95% случаев лежит в пределах 2 средних ошибок среднего. Таким образом, границы 95% доверительного интервала для среднего будет отстоять от выборочного среднего на удвоенную среднюю ошибку среднего, т.е. мы умножаем среднюю ошибку среднего на некий коэффициент, зависящий от доверительной вероятности. Для среднего и разности средних берётся коэффициент Стьюдента (критическое значение критерия Стьюдента), для доли и разности долей критическое значение критерия z. Произведение коэффициента на среднюю ошибку можно назвать предельной ошибкой данного параметра, т.е. максимальную, которую мы можем получить при его оценке.
Доверительный интервал для среднего арифметического : .
Здесь - выборочное среднее;
Средняя ошибка среднего арифметического;
s – выборочное среднее квадратическое отклонение;
n
f = n -1 (коэффициент Стьюдента).
Доверительный интервал для разности средних арифметических :
Здесь - разность выборочных средних;
 - средняя ошибка разности средних арифметических;
- средняя ошибка разности средних арифметических;
s 1 ,s 2 – выборочные средние квадратические отклонения;
n 1 ,n 2
Критическое значение критерия Стьюдента при заданных уровне значимости a и числе степеней свободы f=n 1 +n 2 -2 (коэффициент Стьюдента).
Доверительный интервал для доли :
![]() .
.
Здесь d – выборочная доля;
– средняя ошибка доли;
n – объём выборки (численность группы);
Доверительный интервал для разности долей :
Здесь - разность выборочных долей;
 – средняя ошибка разности средних арифметических;
– средняя ошибка разности средних арифметических;
n 1 ,n 2 – объёмы выборок (численности групп);
Критическое значение критерия z при заданном уровне значимости a ( , , ).
Вычисляя доверительные интервалы для разности показателей, мы, во-первых, непосредственно видим возможные значения эффекта, а не только его точечную оценку. Во-вторых, можем сделать вывод о принятии или опровержении нулевой гипотезы и, в-третьих, можем сделать вывод о мощности критерия.
При проверке гипотез с помощью доверительных интервалов надо придерживаться следующего правила:
Если 100(1-a)-процентный доверительный интервал разности средних не содержит нуля, то различия статистически значимы на уровне значимости a; напротив, если этот интервал содержит ноль, то различия статистически не значимы.
Действительно, если этот интервал содержит ноль, то, значит, сравниваемый показатель может оказаться как больше, так и меньше в одной из групп, по сравнению с другой, т.е. наблюдаемые различия случайны.
По месту, где находится ноль внутри доверительного интервала, можно судить о мощности критерия. Если ноль близок к нижней или верхней границе интервала, то возможно при большей численности сравниваемых групп, различия достигли бы статистической значимости. Если ноль близок к середине интервала, то, значит, равновероятно и увеличение и уменьшение показателя в экспериментальной группе, и, вероятно, различий действительно нет.
Примеры:
Сравнить операционную летальность при применении двух разных видов анестезии: с применением первого вида анестезии оперировалось 61 человек, умерло 8, с применением второго – 67 человек, умерло 10.
d 1 = 8/61 = 0,131; d 2 = 10/67 = 0,149; d1-d2 = - 0,018.
Разность летальностей сравниваемых методов будет находиться в интервале (-0,018 - 0,122; -0,018 + 0,122) или (-0,14 ; 0,104) с вероятностью 100(1-a) = 95%. Интервал содержит ноль, т.е. гипотезу об одинаковой летальности при двух разных видах анестезии отвергнуть нельзя.
Таким образом, летальность может и уменьшится до 14% и увеличиться до 10,4% с вероятностью 95%, т.е. ноль находится примерно по середине интервала, поэтому можно утверждать, что, скорее всего, действительно не отличаются по летальности эти два метода.
В рассмотренном ранее примере сравнивалось среднее время нажатия при теппинг-тесте в четырёх группах студентов, отличающихся по экзаменационной оценке. Вычислим доверительные интервалы среднего времени нажатия для студентов, сдавших экзамен на 2 и на 5 и доверительный интервал для разности этих средних.
Коэффициенты Стьюдента находим по таблицам распределения Стьюдента (см. приложение): для первой группы: = t(0,05;48) = 2,011; для второй группы: = t(0,05;61) = 2,000. Таким образом, доверительные интервалы для первой группы: = (162,19-2,011*2,18 ; 162,19+2,011*2,18) = (157,8 ; 166,6) , для второй группы (156,55-2,000*1,88 ; 156,55+2,000*1,88) = (152,8 ; 160,3). Итак, для сдавших экзамен на 2, среднее время нажатия лежит в пределах от 157,8 мс до 166,6 мс с вероятностью 95%, для сдавших экзамен на 5 – от 152,8 мс до 160,3 мс с вероятностью 95%.
Проверять нулевую гипотезу можно и по доверительным интервалам для средних, а не только для разности средних. Например, как в нашем случае, если доверительные интервалы для средних перекрываются, то нулевую гипотезу отвергнуть нельзя. Для того чтобы отвергнуть гипотезу на выбранном уровне значимости, соответствующие доверительные интервалы не должны перекрываться.
Найдём доверительный интервал для разности среднего времени нажатия в группах сдавших экзамен на 2 и на 5. Разность средних: 162,19 – 156,55 = 5,64. Коэффициент Стьюдента: = t(0,05;49+62-2) = t(0,05;109) = 1,982. Групповые средние квадратические отклонения будут равны: ; . Вычисляем среднюю ошибку разности средних: . Доверительный интервал: =(5,64-1,982*2,87 ; 5,64+1,982*2,87) = (-0,044 ; 11,33).
Итак, разница среднего времени нажатия в группах, сдавших экзамен на 2 и на 5, будет находиться в интервале от -0,044 мс до 11,33 мс. В этот интервал входит ноль, т.е. среднее время нажатия у отлично сдавших экзамен, может и увеличиться и уменьшится по сравнению с неудовлетворительно сдавшими, т.е. нулевую гипотезу отвергнуть нельзя. Но ноль находится очень близко к нижней границе, время нажатия гораздо вероятнее всё-таки уменьшается у отлично сдавших. Таким образом, можно сделать вывод, что различия в среднем времени нажатия между сдавшими на 2 и на 5 всё-таки есть, просто мы не смогли их обнаружить при данном изменении среднего времени, разбросе среднего времени и объёмах выборок.
Мощность критерия – это вероятность отвергнуть неверную нулевую гипотезу, т.е. найти различия там, где они действительно есть.
Мощность критерия определяется исходя из уровня значимости, величины различий между группами, разброса значений в группах и объёма выборок.
Для критерия Стьюдента и дисперсионного анализа можно воспользоваться диаграммами чувствительности.
Мощность критерия можно использовать при предварительном определении необходимой численности групп.
Доверительный интервал показывает, в каких пределах с заданной вероятностью находится истинное значение оцениваемого параметра.
С помощью доверительных интервалов можно проверять статистические гипотезы и делать выводы о чувствительности критериев.
ЛИТЕРАТУРА.
Гланц С. – Глава 6,7.
Реброва О.Ю. – с.112-114, с.171-173, с.234-238.
Сидоренко Е. В. – с.32-33.
Вопросы для самопроверки студентов.
1. Что такое мощность критерия?
2. В каких случаях необходимо оценить мощность критериев?
3. Способы расчёта мощности.
6. Как проверить статистическую гипотезу с помощью доверительного интервала?
7. Что можно сказать о мощности критерия при расчёте доверительного интервала?
Задачи.
И др. Все они являются оценками своих теоретических аналогов, которые можно было бы получить, если бы в распоряжении была не выборка, а генеральная совокупность. Но увы, генеральная совокупность – это очень дорого и часто недоступно.
Понятие об интервальном оценивании
Любая выборочная оценка обладает некоторым разбросом, т.к. является случайной величиной, зависящей от значений в конкретной выборке. Стало быть, для более надежных статистических выводов следует знать не только точечную оценку, но и интервал, который с высокой вероятностью γ (гамма) накрывает оцениваемый показатель θ (тета).
Формально, это два таких значения (статистики) T 1 (X) и T 2 (X) , что T 1 < T 2 , для которых при заданном уровне вероятности γ выполняется условие:
Короче, с вероятностью γ или больше истинный показатель находится между точками T 1 (X) и T 2 (X) , которые называются нижней и верхней границей доверительного интервала .
Одним из условий построения доверительных интервалов является его максимальная узость, т.е. он должен быть насколько это возможно коротким. Желание вполне естественно, т.к. исследователь старается точнее локализовать нахождение искомого параметра.
Отсюда следует, что доверительный интервал должен накрывать максимальные вероятности распределения. а сама оценка быть в центре.
![]()
То бишь вероятность отклонения (истинного показателя от оценки) в большую сторону равна вероятности отклонения в меньшую сторону. Следует также отметить, что для несимметричных распределений интервал справа не равен интервалу слева.
По рисунку выше отчетливо видно, что чем больше доверительная вероятность, тем шире интервал – прямая зависимость.
Это была небольшая вводная часть в теорию интервального оценивания неизвестных параметров. Перейдем к нахождению доверительных границ для математического ожидания.
Доверительный интервал для математического ожидания
Если исходные данные распределены по , то и среднее будет нормальной величиной. Это следует из того правила, что линейная комбинация нормальных величин также имеет нормальное распределение. Следовательно, для расчета вероятностей мы могли бы использовать математический аппарат нормального закона распределения.
Однако для этого потребуется знать два параметра – матожидание и дисперсию, которые обычно не известны. Можно, конечно, вместо параметров использовать оценки (среднюю арифметическую и ), но тогда распределение средней будет не совсем нормальным, оно будет немного приплюснуто книзу. Этот факт ловко подметил гражданин Уильям Госсет из Ирландии, опубликовав свое открытие в мартовском выпуске журнала «Biometrica» за 1908 год. В целях конспирации Госсет подписался Стьюдентом. Так появилось t-распределение Стьюдента.
Однако нормальное распределение данных, использовавшееся К. Гауссом при анализе ошибок астрономических наблюдений, в земной жизни встречается крайне редко и установить это довольно сложно (для высокой точности необходимо порядка 2 тысяч наблюдений). Поэтому предположение о нормальности лучше всего отбросить и использовать методы, не зависящие от распределения исходных данных.
Возникает вопрос: каково же распределение средней арифметической, если оно рассчитано по данным неизвестного распределения? Ответ дает известная в теории вероятностей Центральная предельная теорема (ЦПТ). В математике существует несколько ее вариантов (на протяжении долгих лет формулировки уточнялись), но все они, грубо говоря, сводятся к утверждению, что сумма большого количества независимых случайных величин подчиняется нормальному закону распределения.
При расчете средней арифметической как раз используется сумма случайных величин. Отсюда получается, что среднее арифметическое имеет нормальное распределение, у которого матожидание – это матожидание исходных данных, а дисперсия – .
Умные люди умеют доказывать ЦПТ, но мы в этом убедимся с помощью эксперимента, проведенного в Excel. Смоделируем выборку из 50-ти равномерно распределенных случайных величин (с помощью функции Excel СЛУЧМЕЖДУ). Затем сделаем 1000 таких выборок и для каждой рассчитаем среднюю арифметическую. Посмотрим на их распределение.

Видно, что распределение средней близко к нормальному закону. Если объем выборок и их количество сделать еще больше, то сходство будет еще лучше.
Теперь, когда мы воочию убедились в справедливости ЦПТ, можно, используя , рассчитать доверительные интервалы для средней арифметической, которые с заданной вероятностью накрывают истинное среднее или математическое ожидание.
Для установления верхней и нижней границы требуется знать параметры нормального распределения. Как правило, их нет, поэтому используют оценки: среднюю арифметическую и выборочную дисперсию . Повторюсь, такой способ дает хорошее приближение только при больших выборках. Когда выборки малые, часто рекомендуют использовать распределение Стьюдента. Не верьте! Распределение Стьюдента для средней бывает только тогда, когда исходные данные имеют нормальное распределение, то есть почти никогда. Поэтому лучше сразу поставить минимальную планку по количеству необходимых данных и использовать асимптотически корректные методы. Говорят, достаточно 30 наблюдений. Берите 50 – не ошибетесь.
![]()
T 1,2 – нижняя и верхняя граница доверительного интервала
– выборочное среднее арифметическое
s 0 – среднее квадратичное отклонение по выборке (несмещенное)
n – размер выборки
γ – доверительная вероятность (обычно равна 0,9, 0,95 или 0,99)
c γ =Φ -1 ((1+γ)/2) – обратное значение функции стандартного нормального распределения. По-простому говоря, это количество стандартных ошибок от средней арифметической до нижней или верхней границы (указанным трем вероятностями соответствуют значения 1,64, 1,96 и 2,58).
Суть формулы в том, что берется среднее арифметическое и далее от нее откладывается некоторое количество (с γ ) стандартных ошибок (s 0 /√n ). Все известно, бери и считай.
До массового использования ПЭВМ для получения значений функции нормального распределения и обратной ей использовали . Их и сейчас используют, но эффективнее обратиться к готовым формулам Excel. Все элементы из формулы выше ( , и ) можно легко рассчитать в Excel. Но есть и готовая формула для расчета доверительного интервала – ДОВЕРИТ.НОРМ . Ее синтаксис следующий.
ДОВЕРИТ.НОРМ(альфа;стандартное_откл;размер)
альфа – уровень значимости или доверительный уровень, который в принятых выше обозначениях равен 1- γ, т.е. вероятность того, что математическое ожидание окажется за пределами доверительного интервала. При доверительной вероятности 0,95, альфа равно 0,05 и т.д.
стандартное_откл – среднее квадратичное отклонение выборочных данных. Стандартную ошибку рассчитывать не нужно, Excel сам разделит на корень из n.
размер – размер выборки (n).
Результат функции ДОВЕРИТ.НОРМ – это второе слагаемое из формулы расчета доверительного интервала, т.е. полуинтервал. Соответственно, нижняя и верхняя точка – это среднее ± полученное значение.
Таким образом, можно построить универсальный алгоритм расчета доверительных интервалов для средней арифметической, который не зависит от распределения исходных данных. Платой за универсальность является его асимптотичность, т.е. необходимость использования относительно больших выборок. Однако в век современных технологий собрать нужное количество данных обычно не представляет трудностей.
Проверка статистических гипотез с помощью доверительного интервала
{module 111}
Одной из главных задач, решаемых в статистике, является . Ее суть вкратце такова. Выдвигается предположение, например, что матожидание генеральной совокупности равно какому-то значению. Затем строится распределение выборочных средних, которые могут наблюдаться при данном матожидании. Далее смотрят, в каком месте этого условного распределения находится реальная средняя. Если она выходит за допустимые пределы, то появление такого среднего очень маловероятно, а при однократном повторении эксперимента почти невозможно, что противоречит выдвинутой гипотезе, которая успешно отклоняется. Если же среднее не выходит за критический уровень, то гипотеза не отклоняется (но и не доказывается!).
Так вот с помощью доверительных интервалов, в нашем случае для матожидания, также можно проверять некоторые гипотезы. Это очень просто сделать. Допустим, средняя арифметическая по некоторой выборке равна 100. Проверяется гипотеза о том, что матожидание равно, допустим, 90. То есть, если поставить вопрос примитивно, то он звучит так: может ли такое быть, чтобы при истинном значении средней равной 90, наблюдаемая средняя оказалась равна 100?
Для ответа на этот вопрос дополнительно потребуется информация о среднем квадратичном отклонении и размере выборки. Допустим среднеквадратичное отклонение равно 30, а количество наблюдений 64 (чтобы легко извлечь корень). Тогда стандартная ошибка средней равна 30/8 или 3,75. Для расчета 95% доверительного интервала потребуется отложить в обе стороны от средней по две стандартные ошибки (точнее, по 1,96). Доверительный интервал получится примерно 100±7,5 или от 92,5 до 107,5.
Далее рассуждения следующие. Если проверяемое значение попадает в доверительный интервал, то оно не противоречит гипотезе, т.к. укладывается в пределы случайных колебаний (с вероятностью 95%). Если проверяемая точка выходит за пределы доверительного интервала, то вероятность такого события очень маленькая, во всяком случае ниже допустимого уровня. Значит, гипотезу отклоняют, как противоречащую наблюдаемым данным. В нашем случае гипотеза о матожидании находится за пределами доверительного интервала (проверяемое значение 90 не входит в интервал 100±7,5), поэтому ее следует отклонить. Отвечая на примитивный вопрос выше, следует сказать: нет не может, во всяком случае такое случается крайне редко. Часто при этом указывают конкретную вероятность ошибочного отклонения гипотезы (p-level), а не заданный уровень, по которому строился доверительный интервал, но об этом в другой раз.
Как видим, построить доверительный интервал для среднего (или математического ожидания) несложно. Главное, уловить суть, а дальше дело пойдет. На практике в большинстве случаев используются 95% доверительный интервал, который имеет в ширину примерно две стандартные ошибки по обе стороны от средней.
На этом пока все. Всех благ!